
How I Got 2x Speedup with One Line of Code
November 14, 2013
If you had asked me whether or not it was possible to get a 2x speedup for my LazySorted project by adding a single line of code, I would have told you "No way, substantial speedups can really only come from algorithm changes." But surprisingly, I was able to do so by adding a single line using the __builtin_prefetch function in GCC and Clang. Here's the story about how adding this got me a 2x speedup.
First, some background: My LazySorted project addresses the problem that people often sort an entire list even though they actually only need part of the sorted list, like its middle element, (the median), the last few elements, (the largest elements), or the quartiles. Sorting the whole list in these cases is inefficient, since doing so requires O(n log n) time, when each of the above problems can actually be solved in linear time. My LazySorted project implements a data structure that pretends to be a sorted list, but is not actually physically sorted, and only sorts itself partially and lazily when the programmer requests some of its elements. This allows the programmer to achieve those linear run times while preserving the conceptual simplicity of just sorting the whole list and picking out elements from it.
It does this by using quicksort or quickselect partitions, and keeping track of where the pivots are. To make the data structure easy to work with, I implemented it as a Python extension type in C, and mimicked the API for the Python sorted function and Python lists. So the constructor imitates the builtin sorted function in Python, and instances of the type act like immutable Python lists. By profiling my code, I've discovered that calls to its methods spend the vast majority of their time in the partitioning function, reproduced in a slightly simplified form below:
If you think about it, the partition algorithm itself has good data locality: data is only operated on at two indices in the list, at i and at last_less, which move continuously forward through the array ob_item. The problem is, however, that the things stored in the array are pointers to PyObject's, which means that the pointers need to be dereferenced when I compare the objects that they reference. (This occurs in the IF_LESS_THAN macro). Dereferencing these pointers means that my memory access pattern in fact appears very random, since each PyObject lives on the heap somewhere, and we have to look up that location to compare pointers.
It is this problem that got me the behavior that I detailed in an earlier blog post on LazySorted scaling problems: As the list grows, eventually we can't fit all of its elements into cache, and pretty soon most memory references cause a cache miss. At this point, we eat up the latency of accessing main memory rather than the much lower latency of accessing the cache.
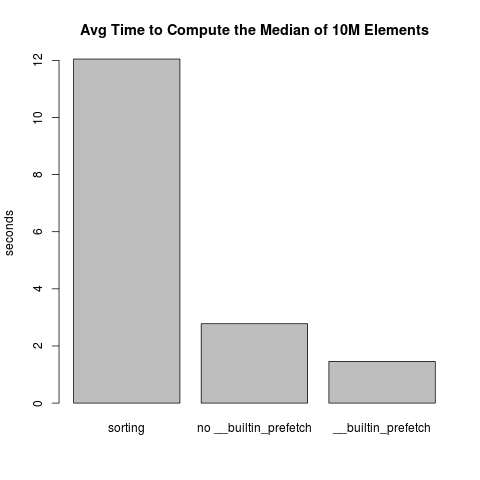
As you can see from that blog post about this problem, I was convinced then that "as far as I can tell there is nothing I can do fix it". But then, my friend Rafael Turner suggested that I look at the GCC builtins to try to improve locality. After some research and experimentation, by adding the single __builtin_prefetch(ob_item[i+3]) line, I was able to improve the speed of finding the median of a random list of 10M elements from an average of 2.78 seconds down to 1.46 seconds, a speedup of 1.9x. This compares to an average time of 12.0 seconds if you use the Python's sorted function and pick off the middle element, an overall speedup of 8.2x. (This is with Python 2.7.3 on Linux 3.5.0-17-generic with this processor).
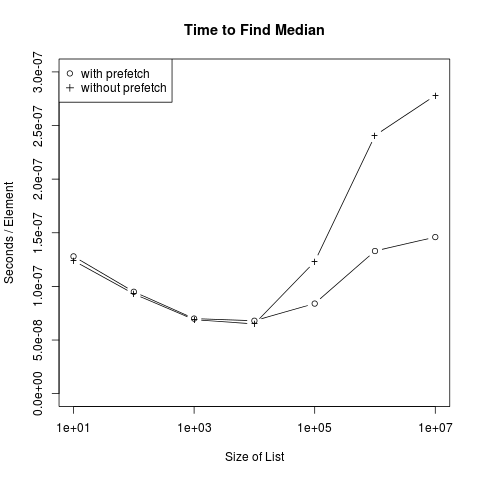
You can see how adding this line of code has little if any detrimental effect for small lists, but dramatically improves scaling for larger lists:
Here is the commit in question. You can see that the meat of it consists of a single line of code, (plus a few macro lines to keep it portable).
So what does the __builtin_prefetch function do? As described on the GCC builtins page and on pages 305-9 in Hennessy's "Computer Architecture" (Ed. 4), it asks your cache to load the referenced address from main memory, making it ready for you when it's time to work with it. It does so without blocking, or otherwise you would have to wait for the fetch to complete and wouldn't get any speedup. So at the same time that the PyObject comparison and list iteration instructions are getting executed, future PyObject's are getting loading into the cache, resulting in the speedup that I observed.
Now, I didn't just "know" to prefetch the PyObject three indices forward in the array. I arrived at this value through experimentation. In particular, I tried a couple of different values and then picked the one that got me the best speedup. (I also experimented with the optional rw and locality arguments to __builtin_prefetch, but saw no substantial differences).
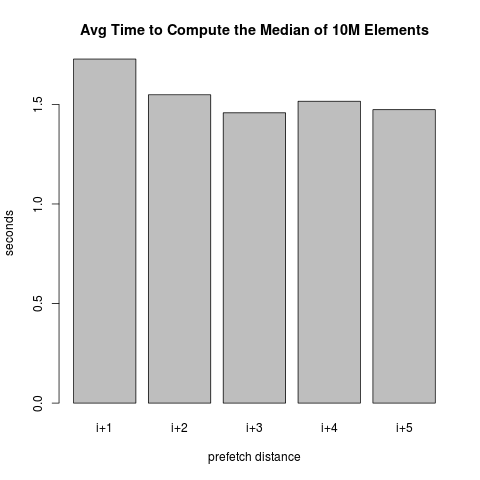
(Of course, as a good Statistician, I chose the optimal parameters in one round of experimentation, and then quoted you the average times after doing another experiment so that the quoted averages would be unbiased).
So that's my story about how I got a 2x speedup by adding just one line of code. The moral of the story, at least for me, is that you can occasionally get substantial improvements by understanding what is actually happening under the hood of your application, rather than fundamentally changing your application itself.
